Jonghyun Ho
Learning CarRacing environment with stable-baselines3
강화학습을 좀 더 쉽게 할 수 있도록 도와주는 라이브러리인 stable-baselines3 를 활용하여 CarRacing 환경을 학습해본다.
환경 및 설치
Windows 10 의 Anaconda 환경
> pip install stable-baselines3[extra]
모델 학습
PPO 알고리즘을 이용하여 학습한다.
# train.py
import gym
import os
from stable_baselines3 import PPO
from stable_baselines3.common.callbacks import EvalCallback
env = gym.make('CarRacing-v0')
log_path = os.path.join('./Training/Logs')
model = PPO('CnnPolicy', env, verbose=1, tensorboard_log=log_path)
ppo_path = os.path.join('./Training/Saved_Models/PPO_car_best_Model')
eval_env = model.get_env()
eval_callback = EvalCallback(eval_env=eval_env, best_model_save_path=ppo_path,
n_eval_episodes=5,
eval_freq=50000, verbose=1,
deterministic=True, render=False)
model.learn(total_timesteps=1000000, callback=eval_callback)
ppo_path = os.path.join('./Training/Saved_Models/PPO_2m_Model_final')
model.save(ppo_path)
학습 진행 상황 확인
학습 도중 Tensorboard 를 활용하여 학습 경과를 확인할 수 있다.
> tensorboard --logdir=./
Tensorboard 실행 후 웹 브라우저에서 http://localhost:6006/ 접속
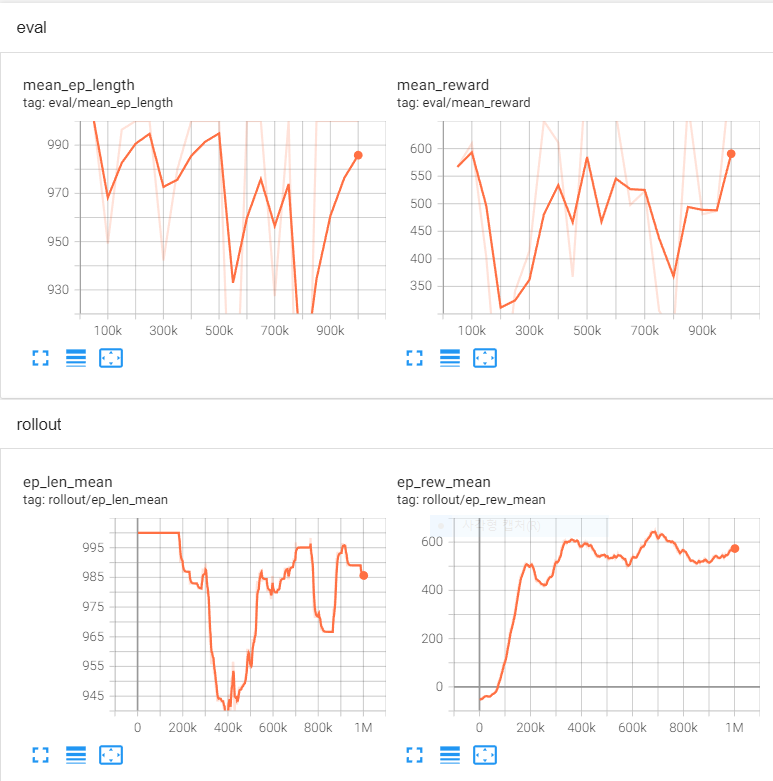
100만 번의 timestep 을 학습하는 동안 rollout/ep_rew_mean 그래프에서는 학습 시 리워드 평균의 값을 확인할 수 있고
eval/mean_reward 그래프에서는 학습한 모델을 중간 중간 평가할 때 기록이 되어 확인할 수 있다.
위 코드에서는 eval_freq=50000 으로 5만 번의 timestep 마다 학습 모델을 평가하고 있다.
학습 모델 평가
저장된 강화학습 모델을 로드하여 CarRacing 환경의 동작을 확인한다.
# test.py
import gym
import numpy as np
from stable_baselines3 import PPO
env = gym.make('CarRacing-v0')
model = PPO.load(
'./Training/Saved_Models/PPO_car_best_Model/best_model.zip', env=env)
obs = env.reset()
episode_reward = 0
done = False
while not done:
env.render()
action, _ = model.predict(obs.copy())
obs, reward, done, info = env.step(action)
episode_reward.append(reward)
print(f'episode_reward: {np.array(episode_reward).mean()}')
env.close()
> python test.py
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
Wrapping the env in a VecTransposeImage.
Track generation: 1111..1393 -> 282-tiles track
episode_reward: 0.8608540925266758
CarRacing 환경에서 실행한 학습 모델의 모든 Reward 평균은 대략 0.86 이 측정되었고, 주행 모습은 다음과 같다.

Reference
Written on June 5th, 2022 by Jonghyun HoFeel free to share!